Artificial intelligence (AI) plays an increasingly important role in the modern world, and an essential element of practical training of AI models is access to the correct data. Generating synthetic data has become a crucial technique to solve problems related to the lack of data or the need to protect privacy. This article will compare methods for generating synthetic data and the benefits of each approach to training AI models.
Synthetic data is artificially generated data that mimics the characteristics of accurate data but is not directly related to specific observations. Generating synthetic data is based on various techniques, such as generative models, data augmentation, and random sample generation.
Generative models such as GANs (Generative Adversarial Networks) and VAEs (Variational Autoencoders) are widely used to generate realistic synthetic data. These models learn to recognize patterns in real-world data and generate similar data. It is worth mentioning that with this method, we depend on the high randomness of the final results.
The data augmentation technique involves introducing artificial modifications to existing data, such as rotating images, changing lighting, or adding noise. This helps increase the diversity of your training data. At the same time, we work with previously selected images, so we are sure that the collected collection meets our criteria.
Random sample generation is a simple approach that generates random data that follows the general characteristics of the training set. It is beneficial when we need to increase the amount of data quickly and effectively.
Our company also faced the challenge of ensuring the appropriate quality and quantity of data for our research and development projects. In search of innovative solutions, we decided to use Unreal Engine. This choice opened up entirely new opportunities for us regarding data generation, bringing several benefits and challenges.
Unreal Engine is a robust environment for creating interactive 3D visualizations, games, and simulations, making it a valuable tool for generating synthetic data. You can use Unreal Engine to create realistic 3D scenes and render images or videos from them, which can be used as training data, especially in the field of machine vision.
Unreal Engine allows you to create advanced simulations of environments that consider the movement of objects, interactions between them, changes in lighting, and even atmospheric conditions. Whether it is the behavior of vehicles, machines or people on the road, on a construction site, in a factory or in a warehouse, whether it is monitoring the area in terms of health and safety or specific risk factors such as fire or smoke – we can reproduce and simulate all these circumstances in the EU.
Additionally, Unreal Engine allows you to program artificial intelligence for game characters. This can be used to generate data regarding characters’ behavior, interactions between them, and decision-making. This data can be used to train models to analyze and understand behavior.
It’s also worth noting that Unreal Engine supports programming languages like C++ and Blueprints, which allows you to program custom behaviors and features in your simulations.
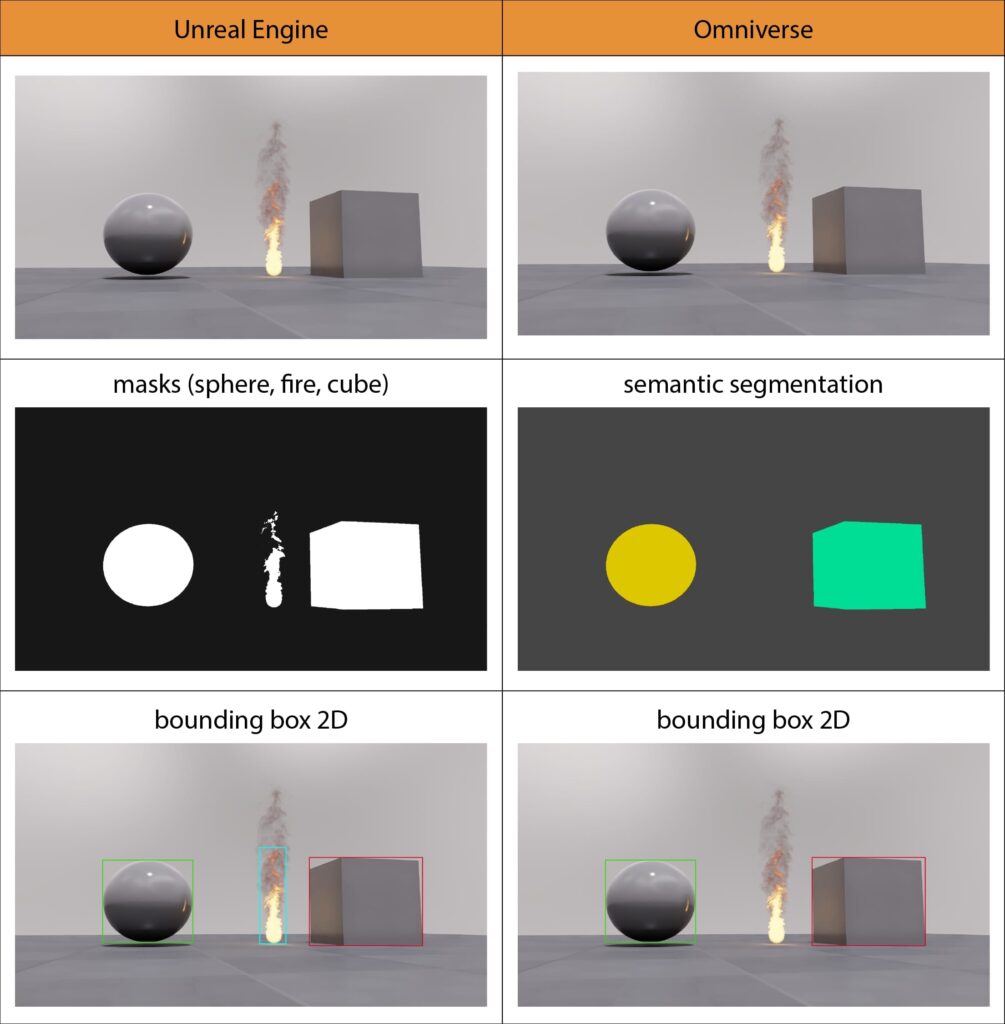
This gateway allowed us to create our own tool for rendering data in the Unreal Engine environment. This was a key and, as it turned out, excellent decision made in the search for effective ways of generating visual data. This innovative plugin has opened up new possibilities for us in creating videos and images with additional information, such as masks, labels with tags identifying object classes, COCO labels, and skeletons, which are necessary for training advanced artificial intelligence models.

Our goal was to create a tool that would allow for the easy and effective generation of extensive training data while eliminating the need to mark or label them manually. Thanks to this, we effectively reduced the time needed to prepare data.
We also wanted the tool to be flexible and scalable to adapt the generated data to the specific requirements of each project.
Our plugin allows you to render high-quality single images and video sequences. The user has complete control over rendering parameters and the amount of randomization, which allows the generated data to be tailored to specific design needs.
Observing current trends, we are convinced that our approach to synthetic data generation methods is a well-chosen direction. A very advanced Nvidia project – Omniverse – is heading in the same direction.
Nvidia Omniverse is a platform that integrates various tools and engines for creating 3D visualizations, simulations, design, rendering, and working with content in real-time. It offers advanced tools not only for creating 3D visualizations but also possibilities and tools for generating synthetic data directly for machine learning needs, i.e., images and videos with an additional layer of annotation.
One of the primary motivations for creating Omniverse was to create a virtual environment for machine learning. Therefore, we decided to look there, explore the possibilities, and compare them with our current methods of achieving similar goals.
It is important to emphasize that the opinions presented here result from preliminary testing rather than in-depth research.
Omniverse
What looks appealing:
- Available plug-ins allow you to conveniently switch between Omniverse and Unreal, 3DS max, Blender, and other programs of this type and work in them in real-time.
- Due to the USD – Universal File Description format promoted by Nvidia, you can work with assets in any program.
- A convenient system for saving operations on layers and the ability to save operations in the USD format
- An exciting asset search engine – DeepSearch. It uses computer vision to analyze existing 3D models and enables search using natural language.
- It is worth keeping an eye on the developed plugin connecting ChatGPT with the DeepSearch search engine, using the local library’s resources for automated scene composition.
- Possible selective use of programs from the Omniverse ecosystem to create simulations. Export in VDB format allows rendering in any package.
- Assuming we have a properly constructed scene and the randomization mechanics coded in it, the system of generating renders with appropriate tags/labels seems friendly and promisingly efficient.
- Interface for efficiently assigning classes to objects.
- The fire and smoke setting system seems more straightforward than Niagara/Fluid in Unreal, a bit like the system from Embergen (its flexibility and the ability to introduce randomization remain on the list of things to test).
What was discouraging:
- Omniverse still looks like a fresh product, served in a lovely package, but it can be improved.
- The lack of some amenities or keyboard shortcuts and the need to select them from the menu gives the impression of austerity, e.g., the grid view is not hidden by default for the camera during rendering, and there is no quick shortcut to turn off the visibility of all such “working” indicators.
- There are still very few training materials of satisfactory quality available.
- Things often look different in tutorials than in reality (this is probably due to the rapid development of the program and the lack of an equally dynamic pace in refreshing tutorials). Even in official training materials, there are situations where something should work for the instructor, but it does not work, or it “breaks down.”
- The official documentation needs to be corrected.
- Problems in using localhost are one of the main advantages of the work system promoted by Nvidia. The uncertainty of this system is evidenced by the number and content of threads on the technical support forum. Many users report problems with the installation itself, and then with the system suddenly stopping working and disappearing (along with the projects saved on it = loss of all work). There may be a correlation between this phenomenon and Windows updates.
- The technical support forum (so far tested only on one example regarding localhost) did not turn out to be very helpful, i.e., the reaction from other users appeared quite quickly, but the response of the Nvidi representative was not too fast. It did not end with solving the problem; instead, they are groping in the dark and recommending the same ineffective procedures.
- Compared to Unreal, there are much fewer ready-made assets available. The possibilities of manipulating them inside the Omniverse itself are much smaller, e.g., a ready-made warehouse building is available instead of blocks to build your warehouse, so to change the size arrangement of walls or the shape of the roof/windows, you need to convert it in another 3D graphics program.
- Managing objects and materials assigned to them in a scene is not convenient and transparent enough at first glance. Materials are treated as individual objects (it’s easy to get messy if you don’t take care of the folder structure).
- Omniverse provides its tools as separate modules, clearly separating graphic work from programming work. Typical graphic work is limited to building 3D scenes from collected or previously created 3D models, materials, and textures or directing films/animations.
To set randomizations and generate various data, typically for AI training, you must use predefined modules that require programming preparation (Python).
In Unreal, a graphic designer could do this from start to finish.
- It can be seen that Nvidia, in its tools, tries to combine various functions known from longer existing tools and programs on the market while breaking their functionalities into separate modules. Hence, the 3D scene setting module refers to Unreal, as if it wanted to achieve its effects, but with an interface and approach similar to Blender and Substance Painter. Unfortunately, this basic module only allows you to perform static parts; work with animation or randomization should be transferred to another module. It can be assumed that such a division allows specialized teams to focus on the part of the work that interests them, but on the other hand, jumping through modules is tiring for someone who wants to carry out a multi-threaded project from start to finish.
- Referring to the above, Unreal Engine allows a graphic designer to prepare the data generation process from start to finish in one environment. To give the same effect, Omniverse requires the graphic designer to have programming skills and use various modules or split the data generation process between the graphic designer and the programmer.
- Omniverse emphasizes places other than data generation itself. Still, for now, the main priority is the AI training itself in the virtual environment and not the visual side of this environment. Unreal has been developing from the beginning in terms of visual aspects, and it has been on the market much longer, so it is more prosperous and stable in this respect.
- Even if you have appropriately qualified graphic designers and programmers familiar with Omniverse, you can still generate synthetic data faster. You must still do the same preparatory work as in Unreal, i.e., prepare assets, scenes, mechanics, and randomizations.
- At the moment (November 20, 2023), the significant disadvantage is that it is impossible to render annotations for fire and smoke simulation (flow plugin).
Generating synthetic data, no matter in which environment we choose, is a powerful tool that can support the training of artificial intelligence models, both in the absence of data and to protect privacy. We will watch with pleasure and bated breath the growing capabilities of tools such as Omniverse and Unreal Engine. As generative technologies develop, the role of synthetic data will become increasingly important in artificial intelligence, and combining different techniques for generating synthetic data will allow for even better adaptation to the specific needs of different projects.
In the next post, we will present a practical example of using Omniverse to generate synthetic data.