In the ever-evolving landscape of computer vision and AI, fundamental models have emerged as powerful tools trained on vast datasets unsupervised. Following the success of these models in natural language processing, recent interest in the academic community has turned to unsupervised learning from images or video.
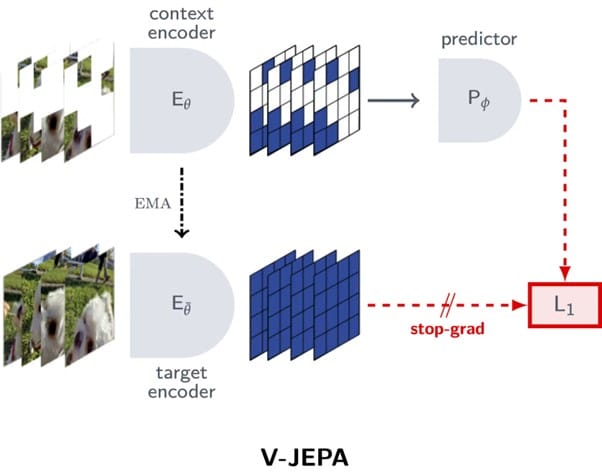
V-JEPA (publication: v-jepa) represents the latest iteration in unsupervised learning of deep learning models based on visual features. Unlike previous work (publication: i-jepa), authors have focused on a model capable of processing information from video recordings (spatiotemporal information) rather than just images (spatial data) – hence the appropriate prefixes “V” and “I.” In both of these publications, a key aspect is the learning process, which consists of defining independent variables (information based on which predictions are made) and dependent variables (information that we try to predict).
Unsupervised learning, also called self-supervised learning, involves pre-training a neural network to model input data and find correlations within the data itself. In the case of natural language, such a network may attempt to predict missing (hidden) words in sentences to ensure logical coherence or (as in the case of ChatGPT) predict the next word based on the entire text history preceding it. Similarly, for images or videos, by hiding parts of the image/frames, we can use a neural network to fill in artificially generated gaps, thereby teaching it about the general structures of objects in the images.
However, recent research has indicated that predicting individual pixels’ values takes more work to teach a neural network to build semantically valuable representations. Researchers have cited reasons such as the immense complexity of solution spaces (spaces consisting of all possible combinations of pixel values) and reliance on continuous input signal values rather than discrete ones (as in the case of text).
The Joint Embedding Predictive Architecture proposed by Yann LeCun for self-supervised learning in visual signals (images, videos) differs from other such solutions in one critical aspect. Namely, the prediction made by the model is not performed in the signal space (pixels) but in an abstract, semantically rich space. LeCun argues for the necessity of using this particular learning method by suggesting that the signal space contains a plethora of unnecessary information that cannot be effectively modeled due to the sheer complexity of the problem. Therefore, in his architecture, we allow the network to filter semantically valuable information from raw signal information, simplifying the situation and making its solution much more effective.
Noctuai boasts its proprietary platform for implementing various video analytics models, AICam. If anyone is interested in deploying specialized solutions based on innovative techniques such as those described in this blog, we invite you to contact us. With over ten years of experience in IT and deployments across industries from Oil & Gas to healthcare worldwide, we are well-equipped to meet diverse needs.